The Interview Trap: The "Live-Query" and "Reboot-and-Pray" Catastrophe
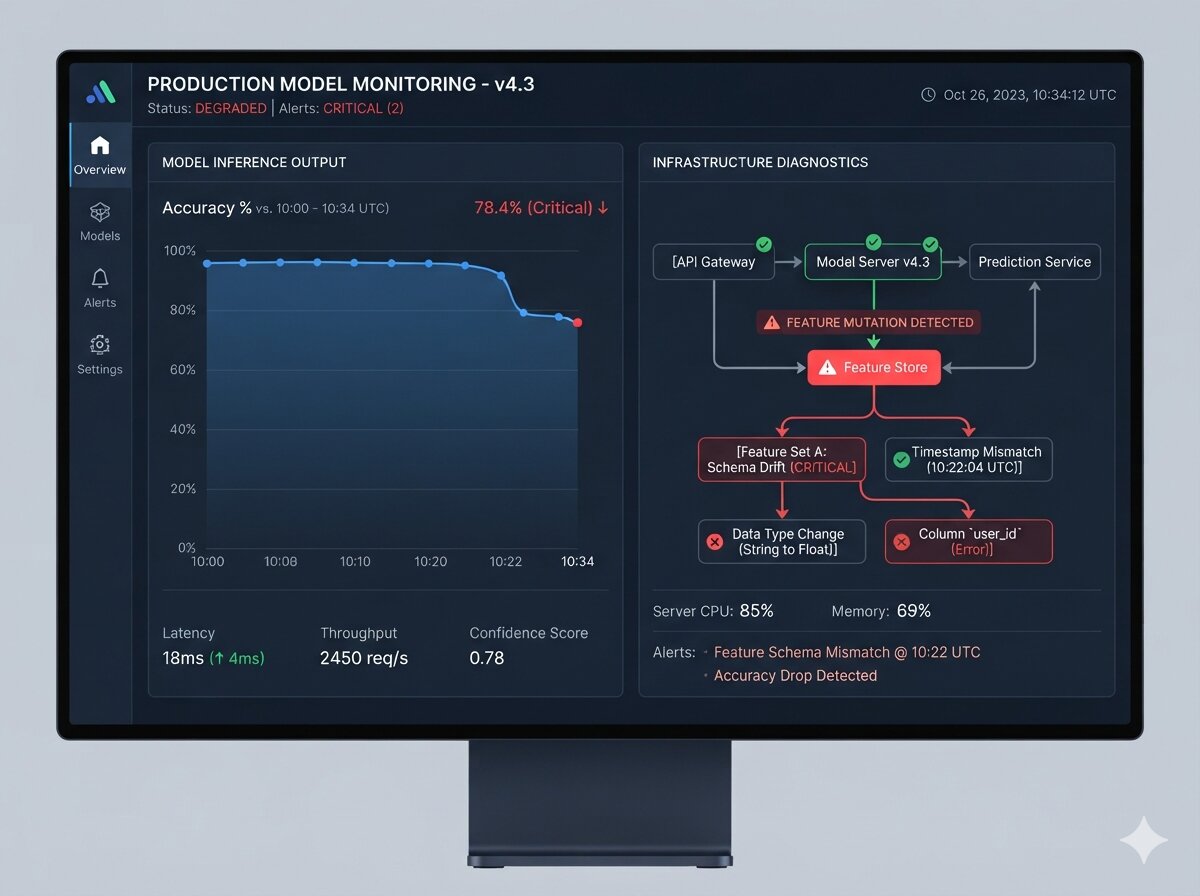
The interviewer presents a high-stakes infrastructure emergency: "It is Black Friday peak hour. Your primary relational database, which processes all real-time order transactions, suddenly spikes to 100% CPU utilization, stops responding to health checks, and crashes. The application tier is throwing massive connection timeout errors, and global revenue has completely flatlined. What is your immediate technical response?" Most candidates tank this round by panicking or suggesting disastrous live-production debugging: "I'd immediately SSH into the primary database server, run a query profile trace to see which transaction is locking the tables, kill the rogue process, and reboot the database service." Stop. Trying to run diagnostic queries or rebooting a thrashing primary database while millions of concurrent users are actively hitting your application servers will corrupt transaction states and trigger cascading failures across your entire microservice grid. In a FAANG system design or infrastructure execution round, panels look for your Blast-Radius Isolation, Automated Failover Execution, and Transactional State Preservation.
The Core Framework: The "FAILOVER-SHIELD" Method
When a core transactional database collapses under peak load, your primary objective is system survival and revenue restoration, not immediate root-cause investigation. You must instantly isolate the broken node, promote healthy infrastructure, and throttle incoming load to allow the system to recover safely.
1. F-ailover Automation Activation
Instantly promote a healthy, synchronized replica to handle production traffic.
- The Strategy: Leverage your database cluster management plane (e.g., AWS Aurora Global Database failover or an orchestrator layer) to promote a Read Replica to Primary status.
- The Soundbite: "My immediate priority is to restore the transaction pipeline without touching the broken database node. I will trigger an automated database failover. The cluster orchestrator will instantly strip the crashing instance of its primary status and promote our healthiest, lowest-lag Multi-AZ Read Replica to become the new Read-Write Primary node, updating our internal cluster endpoints."
2. A-pplication Connection Pool Shedding
Force application servers to break stuck database hooks to prevent connection starvation.
- The Strategy: Instruct the application tier to instantly flush and reset dead database connection pools (like HikariCP) to point to the newly promoted primary endpoint.
- The Soundbite: "Promoting the replica isn't enough if our application servers are choked with dead connections. I will execute a rolling configuration reload across our microservices to drop the exhausted connection pools. This forces our application instances to instantly shed dead connections and open clean, functional sockets to the new primary database endpoint."
3. I-solate the Crashing Monolith
Completely sever the network pipeline to the broken database node to protect cluster integrity.
- The Strategy: Modify security groups or network Access Control Lists (ACLs) to block all inbound traffic to the failed instance.
- The Soundbite: "While the new primary takes over, we must quarantine the failed node. I will update our network security groups to cut off all application connections to the broken instance. This stops cascading retries from continuing to thrash its CPU, freezes its memory state for forensic analysis, and prevents it from accidentally processing split-brain writes if it suddenly wakes back up."
4. L-oad Shedding and Circuit Breakers
Protect the freshly promoted replica from immediately getting crushed by the backlogged traffic spike.
- The Strategy: Trip the application-layer circuit breakers (e.g., Resilience4j) to reject non-essential requests and place the system into partial degradation mode.
- The Soundbite: "To ensure our newly promoted replica doesn't immediately crash from the backlogged traffic surge, we must activate load shedding. We will trip our application circuit breakers. For the next 5 minutes, non-essential calls like user profile updates or recommendation engines will fail-fast with a clean cached response, allowing the new database node to stabilize and catch up on the core order transaction queue."
5. O-ffline Snapshot Logging and Dumping
Capture a forensic snapshot of the failed database's state before running any recovery or diagnostic routines.
- The Strategy: Trigger an automated volume snapshot (e.g., AWS EBS snapshot) and export the active engine status logs to an isolated storage bucket.
- The Soundbite: "With system traffic stabilized, we preserve the diagnostic trail. Before we reboot or modify the isolated node, I will trigger a complete infrastructure volume snapshot and dump its active database engine status records. This gives our database administration team a clean, uncorrupted replica of the failure state to debug completely offline without risking production."
6. V-erify Data Parity and Log Sequencing
Run immediate transactional reconciliation scripts to ensure zero data loss occurred during the failover window.
- The Strategy: Compare Log Sequence Numbers (LSN) or Write-Ahead Logs (WAL) between the old primary and the promoted replica to detect replication lag gaps.
- The Soundbite: "Next, we must verify transactional honesty. I will have our data integrity scripts compare the final Write-Ahead Logs and transaction sequence numbers between the isolated instance and our active primary. If a tiny sub-second replication lag caused any data gaps during the crash, we isolate those specific transaction IDs to run targeted reconciliation loops via our payment ledger."
7. E-xecute Throttled Traffic Ramp-up
Gradually dial down the application circuit breakers to ease the system back to full production capacity.
- The Strategy: Slowly lower the error-rate thresholds on your API gateways, allowing live user traffic to return in controlled canary steps.
- The Soundbite: "We will now ease out of emergency mode. We won't open the floodgates all at once. We will adjust our API gateway configuration to slowly scale down our circuit breakers, routing 10% of full checkout traffic through, tracking database IOPS and replication health metrics, and ramping up to 100% capacity over a managed 15-minute window."
8. R-etrospective Optimization Blueprint
Lead a structured post-incident review to engineer permanent system immunities against this failure mode.
- The Strategy: Identify the root cause—such as missing indices, suboptimal query execution plans, or bad connection limits—and implement permanent system guardrails.
- The Soundbite: "Once peak traffic concludes safely, I will lead a blameless post-mortem. We will stand up the snapshot of the crashed node in an offline sandbox to find the exact root cause—whether it was an unindexed query under load or connection pool exhaustion. We'll convert these findings into permanent engineering fixes: adding strict statement timeouts, optimizing our read/write splitting architecture, and implementing automated query throttling at the proxy layer."
The Comparison: Bad vs. Good
- Bad Answer: "I would jump on the server, run some query kills to free up the CPU, restart the database engine right there in production, and hope that our application servers reconnect on their own when it comes back up." (Extreme risk of data corruption, prolongs outage duration, completely blind to distributed systems realities).
- Good Answer: "I will protect our platform viability by triggering an automated replica promotion, forcing application servers to shed dead connection pools, quarantining the broken node to avoid split-brain writes, and utilizing application-layer load shedding to let our new primary cluster stabilize safely." (Highly disciplined, architecturally robust, prioritizes business survival).
Master Distributed Systems Scale Rounds
When a mission-critical storage layer fails during peak volume, a technology leader's fundamental systemic intuition is put to the test. Showing an interview panel that you can execute a highly coordinated, zero-downtime infrastructure failover while protecting system state and throttling traffic spikes demonstrates elite technical command. The FAILOVER-SHIELD protocol provides the precise structural playbook needed to navigate massive database catastrophes with complete executive composure.
The Kracd Prep Kits offer exhaustive technical deep-dives covering high-availability data topologies, split-brain mitigation tactics, and distributed transaction boundary patterns.
- For PMs: Learn how backend database infrastructure choices directly impact business continuity, SLA targets, and user trust during high-traffic events with the PM Prep Guide.
- For TPMs: Master advanced cross-region replication mechanics, automated health check engineering, connection pool optimization, and failover orchestration with the TPM Prep Kit.
FAQs
Q: How do you prevent a "split-brain" scenario during an automated failover?A: You must implement a strict quorum or fencing mechanism. A split-brain scenario happens when the old primary database recovers from a transient network blip and assumes it is still the authoritative leader, while your cluster manager has already promoted a replica, leading to conflicting data writes. To prevent this, your cluster orchestration plane must use a fencing token or explicitly isolate the old node at the network layer (fencing) before allowing the newly promoted replica to accept write traffic.
Q: If we use asynchronous replication, won't a sudden failover guarantee some data loss?A: Yes, there is an inherent trade-off between performance (asynchronous) and absolute data safety (synchronous). If your architecture relies on asynchronous replication to minimize write latency, a sudden crash means a tiny fraction of a second of data in transit might not have reached the replica. To mitigate this during a crash, you must cross-reference your application-layer audit logs or payment gateway events against the database logs post-incident to reconstruct any missing transactions cleanly.
Q: Should we automatically fail back to the original primary database once it is fixed?A: No, never execute an automated failback. Failing back is a highly sensitive, complex operation that involves re-syncing data direction, rebuilding indexes, and shifting production traffic all over again. Once a replica has been successfully promoted to primary status and production is stable, let it remain the primary node. Treat the old, recovered database as a fresh blank slate, configure it to join the cluster as a clean read replica, and let data replicate naturally.


.jpg)